
Distributed Systems are complex. There is no doubt about it. But thanks to the experts and the years of experience and experimentation, we now have some of the reference architectures.
In this article, I will be discussing four distributed architectural patterns along with their pros and cons. This will be a good reference point for someone who is just starting out or designing an architecture for their next big project.
Table of Contents
Modern Three Tier Architecture
This architecuture is not new 😀
This architecture was there since early 2000.
I also remember the time when I built my first website. Somewhere in the year 2013. Infact, many of us are pretty well versed with this architecture.
I’m talking about this.

However, now when I look back to these architectures I see some horrible things that happened on the way. It might not be that bad for the people who were working with distributed architecture in those times but to me, it’s hard to understand those choices now. Enterprise was a scary place back then (it still is but comprehensible) and PHP was the most liked language on the web. Well, times have changed and sure does our understanding of the architecture and PHP is almost dead :p
So, do you see the horrible parts?

JSP is horrible.
EJB is horrible.
Oracle is… well… horrible. (And this is strictly in the context of distributed system)
I know, I know, these weren’t really distributed systems but this sure was the start.
We still build applications similarly. A comparable system that is pretty scalable and familiar with today’s standard is this.

I’ve just changed the labels and replaced oracle database with cassandra to handle distributed load.
I’m sure you’ve worked with this architecture before or even working with one right now.
One good thing that happened with this architecture is that we moved most of the logic to the frontend. This thing has enabled us to push more and more compute-heavy tasks to the frontend. Making use of the client’s machine to perform compute-intensive tasks (such as building a rich user experience) have found a way to offload our applications. Now applications can focus on two things well, business and data.
Since you are performing most of the business of constructing a useful information
Now let’s see how can we scale this architecture to serve millions of customers.
Scale Modern Three Tier Architecture To Handle Millions Of Users
Let’s say that our business grew many folds and now we have to handle millions of users request.
The first thing that I would do is clone the frontend servers and application servers. I will also have to install some kind of reverse proxy or load balancer to manage and route the load to the correct application server.
Not only this, in order to scale them horizontally, I will have to come up with a way to make my application stateless. Because now the two requests coming from the same user can be served by two different servers in the backend. I will have to come up with a way to make all my applications stateless or push the state to frontend.
This transition was not easy. It has seen a big evolution from stateful applications to the stateless applications. Since we had to scale horizontally, it was a necessity for the system to be stateless. That was the era when OAuth standards came into existence.
Let’s have a look at the reference architecture for the same.

Nowadays we take this architecture as granted mostly because of the advancements in the technological space and cheap hardware. But this was a great deal back then.
A distributed database like Cassandra is required in order to handle heavy load and maintain the availability and consistency at the same time (keeping in mind the CAP theorem).
With this architecture we have a clear distinction of all three tiers.

I’m keen and pulled towards explaining what each of these components and layer is responsible for, but this article is just about giving you a high-level view of the architecture. I will dedicate another article where I will talk about different components that are involved in building a distributed architecture. Do subscribe to the blog to get the update directly in your inbox.
Strengths
- Rich frontend framework (Scale, UX)
- Hip, scalable middle-tier
- Basically infinitely scalable data tier
Weaknesses
Not really but only thing that was in the past was
- State in the middle tier. Write application in a way that is stateless.
Moving on… next I want to touch upon another popular architecture that is used quite a lot and a backbone for slack.
Sharded Architecture
To understand a sharded architecture. Let’s start by building the simplest architecture. And in my opinion a simplest architecture would be like:
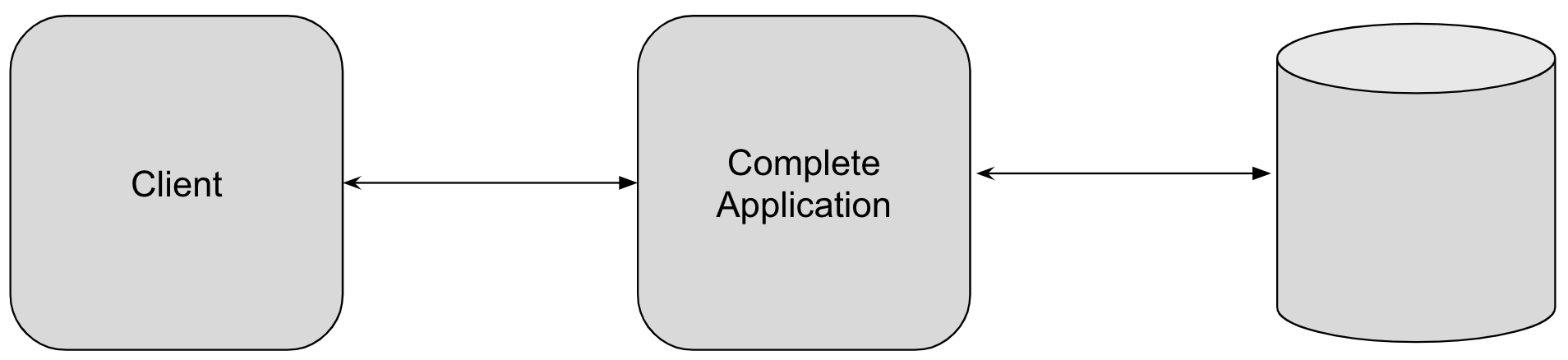
Just by looking at this you can think of the simplicity of the entire system.
There are clients talking to our application, the application is talking to database and serving the clients. Life is so good.
And trust me you would want to live in this picture.
But… life is not always the same.
Overtime your application will grow in popularity and the number of clients will increase. Soon before you know it your application will start slowing down. You will start experiencing latency in the overall system. That time you would have to come out of your perfect world and find some solutions,
Well, sharded architecture lets you stay in that beautiful zone.
You just clone your entire system including the database and keep on serving more and more clients. This is not like the modern three-tier architecture where you would spin up a new application as the load increase and redirect the traffic using a load balancer. In sharded architecture, you would replicate the entire system into a new system which will be isolated from other systems. It would seem like a non-distributed system in itself. Your application wouldn’t have to be written in some special way, everything will work the same way as before and you would be serving more clients at the same time.
And with the help of a router, you will direct the subset of the traffic to any one of the shard.
This re-routing of the traffic will be handled by a complex piece of hardware and software which we will call router.
So, the overall architecture would look something like this:

In this architecture, the router stays in between the clients and the shard. And based on some of the property on the client, he would redirected to any of the shard. That could be client’s geolocation data or the user id hashed to identify the respective shard.
A very good example of a shared architecture is Slack. Slack uses organization at its heart. Everything revolves around the organization in Slack world. Every person will belong to any of the organization. And the organization is a good place to shard the system. It is a complete world in itself and can very well lie in its own shard.
So far everything looks good. Life seems to be going well (except for the router part, but that’s like a one time thing). But there are times when Sharding Attacks. Let’s take a loot at time when sharding attacks.
When Sharding Attacks
Sharding usually attacks when your user base in one of your shards grows large enough that it no longer fits in your database. And when this thing happens you will start noticing the latency in the overall performance of your application.
That point you would have to step back and analyze the system from the bird’s eye view to see what’s exactly happening.
If your application is a write-heavy application and your writes are bottlenecking because of the database, you should look for caching solutions. That would probably speed up the writes.
On the contrary, if your application is a read-heavy application then you can come up with some other database configuration such as Master-Slave configuration where you can serve all the reads from the read replicas and writes will happen through one dedicated master database.
Let’s take a pause for a second and understand the architecture that you can follow in order to serve more reads from your database.

There will be a zookeeper somewhere that will take care of the tasks such as leader election and managing the situations where there is a partition etc…
The above configuration is not part of the shard this is just to give you a bit context how the configuration will look like. The real complexity kicks in when you integrate this system with your existing shard.
Let’s plug this configuration with the shard architecture and it would look something like this:

This looks complex, doesn’t it?
Well, it is. Here each shard is divided on the basis of some key. That key could be as simple as a user id or an organization id (probably in case of Slack). And to achieve this there will be some kind of consistent hashing algorithm running in the background to identify where the data should be stored. Each database cluster will have a list of key index that would help in quick retrieval of the data.
So far so good.
But now comes the partition.
Partition Happens
Partition is a hard reality. You cannot escape it. The partition doesn’t have a fixed cause, it could happen for N number of reasons.
Sometimes there could be a long GC pause, switches break, routers breaks, natural calamities could break the underground cables.
So, when partition happens the communication between the nodes breaks. Suddenly, your application faces downtime. But thanks to our configuration the downtime is only in respective to write operations, the reads stills could happen simultaneously.

Meanwhile, the zookeeper takes care of re-electing the new leader in the connected space.

The entire process is pretty complex. But still this is not the entire picture.
There is one more scenario that will happen next and that is when the partition goes away.
The partition is not gonna stay for long, it would go away at some time and then you will be left with two masters.
This is a scary situation.

Well ZooKeeper takes care of resolving this scenario as well. But the complexity is high.
Cool, this brings me to the strengths and weaknesses of the sharded architecture.
Strengths
- Client Isolation is easy (Data and deployment)
- Known simple technologies
Weaknesses
- Complexity
- No comprehensive view of the data (ETL)
- Oversized Shards
Conclusion
This brings us to the closure of this article. Initially I was thinking of explaining four distributed architectures including Lambda and Events architecture but already this article has crossed 1500 words and also I want to take some rest now 😀
I hope you picked up theimportant pieces from these two reference architectures. These are most commonly used architectures and probably will be there forever with some twists.
Let me know what you think about these architectures in the comments below.
And don’t forget to subscribe to the weekly emails about the latest articles posted on this website.